kafka
1、Kafka是什么
在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算。
KAFKA + STORM +REDIS
• Apache Kafka是一个开源消息系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。
• Kafka最初是由LinkedIn开发,并于2011年初开源。2012年10月从Apache Incubator毕业。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
• Kafka是一个分布式消息队列:生产者、消费者的功能。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。
• Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。
• 无论是kafka集群,还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性2、JMS是什么
2.1、JMS的基础
JMS是什么:JMS是Java提供的一套技术规范
JMS干什么用:用来异构系统 集成通信,缓解系统瓶颈,提高系统的伸缩性增强系统用户体验,使得系统模块化和组件化变得可行并更加灵活
通过什么方式:生产消费者模式(生产者、服务器、消费者)jdk,kafka,activemq……
2.2、JMS消息传输模型
• 点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息推送到客户端。这个模型的特点是发送到队列的消息被一个且只有一个接收者接收处理,即使有多个消息监听者也是如此。
• 发布/订阅模式(一对多,数据生产后,推送给所有订阅者)发布订阅模型则是一个基于推送的消息传送模型。发布订阅模型可以有多种不同的订阅者,临时订阅者只在主动监听主题时才接收消息,而持久订阅者则监听主题的所有消息,即时当前订阅者不可用,处于离线状态。
queue.put(object) 数据生产
queue.take(object) 数据消费
2.3、JMS核心组件
• Destination:消息发送的目的地,也就是前面说的Queue和Topic。
• Message :从字面上就可以看出是被发送的消息。
• Producer: 消息的生产者,要发送一个消息,必须通过这个生产者来发送。
• MessageConsumer: 与生产者相对应,这是消息的消费者或接收者,通过它来接收一个消息。通过与ConnectionFactory可以获得一个connection
通过connection可以获得一个session会话。
2.4、常见的类JMS消息服务器
JMS消息服务器 ActiveMQ
分布式消息中间件 Metamorphosis
分布式消息中间件 RocketMQ
.NET消息中间件 DotNetMQ
基于HBase的消息队列 HQueue
Go 的 MQ 框架 KiteQ
AMQP消息服务器 RabbitMQ
MemcacheQ 是一个基于 MemcacheDB 的消息队列服务器。3、为什么需要消息队列(重要)
消息系统的核心作用就是三点:解耦,异步和并行
4、Kafka核心组件
• Topic :消息根据Topic进行归类
• Producer:发送消息者
• Consumer:消息接受者
• broker:每个kafka实例(server)
• Zookeeper:依赖集群保存meta信息。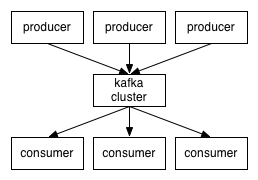
5 关于kakfa集群部署在我的其他文档中有 可以自己查找
6 Kafka常用操作命令
• 查看当前服务器中的所有topic
bin/kafka-topics.sh --list --zookeeper zk01:2181
• 创建topic
./kafka-topics.sh --create --zookeeper mini1:2181 --replication-factor 1 --partitions 3 --topic first
• 删除topic
sh bin/kafka-topics.sh --delete --zookeeper zk01:2181 --topic test
需要server.properties中设置delete.topic.enable=true否则只是标记删除或者直接重启。
• 通过shell命令发送消息
kafka-console-producer.sh --broker-list kafka01:9092 --topic itheima
• 通过shell消费消息
sh bin/kafka-console-consumer.sh --zookeeper zk01:2181 --from-beginning --topic test1
• 查看消费位置
sh kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --zookeeper zk01:2181 --group testGroup
• 查看某个Topic的详情
sh kafka-topics.sh --topic test --describe --zookeeper zk01:21813 kafka总结
kfaka是什么东西?
类JMS消息队列,结合JMS中的两种模式,可以有多个消费者主动拉取数据,在JMS中只有点对点模式才有消费者主动拉取数据。
kafka是一个生产-消费模型。
Producer:生产者,只负责数据生产,生产者的代码可以集成到任务系统中。
数据的分发策略由producer决定,默认是defaultPartition Utils.abs(key.hashCode) % numPartitions
Broker:当前服务器上的Kafka进程,俗称拉皮条。只管数据存储,不管是谁生产,不管是谁消费。
在集群中每个broker都有一个唯一brokerid,不得重复。
Topic:目标发送的目的地,这是一个逻辑上的概念,落到磁盘上是一个partition的目录。partition的目录中有多个segment组合(index,log)
一个Topic对应多个partition[0,1,2,3],一个partition对应多个segment组合。一个segment有默认的大小是1G。
每个partition可以设置多个副本(replication-factor 1),会从所有的副本中选取一个leader出来。所有读写操作都是通过leader来进行的。
特别强调,和mysql中主从有区别,mysql做主从是为了读写分离,在kafka中读写操作都是leader。
ConsumerGroup:数据消费者组,ConsumerGroup可以有多个,每个ConsumerGroup消费的数据都是一样的。
可以把多个consumer线程划分为一个组,组里面所有成员共同消费一个topic的数据,组员之间不能重复消费。kafka生产数据时的分组策略
默认是defaultPartition Utils.abs(key.hashCode) % numPartitions
上文中的key是producer在发送数据时传入的,produer.send(KeyedMessage(topic,myPartitionKey,messageContent))kafka如何保证数据的完全生产
ack机制:broker表示发来的数据已确认接收无误,表示数据已经保存到磁盘。
0:不等待broker返回确认消息
1:等待topic中某个partition leader保存成功的状态反馈
-1:等待topic中某个partition 所有副本都保存成功的状态反馈 broker如何保存数据
在理论环境下,broker按照顺序读写的机制,可以每秒保存600M的数据。主要通过pagecache机制,尽可能的利用当前物理机器上的空闲内存来做缓存。
当前topic所属的broker,必定有一个该topic的partition,partition是一个磁盘目录。partition的目录中有多个segment组合(index,log) partition如何分布在不同的broker上
int i = 0
list{kafka01,kafka02,kafka03}
for(int i=0;i<5;i++){
brIndex = i%broker;
hostName = list.get(brIndex)
}consumerGroup的组员和partition之间如何做负载均衡
最好是一一对应,一个partition对应一个consumer。
如果consumer的数量过多,必然有空闲的consumer。
算法:
假如topic1,具有如下partitions: P0,P1,P2,P3
加入group中,有如下consumer: C1,C2
首先根据partition索引号对partitions排序: P0,P1,P2,P3
根据consumer.id排序: C0,C1
计算倍数: M = [P0,P1,P2,P3].size / [C0,C1].size,本例值M=2(向上取整)
然后依次分配partitions: C0 = [P0,P1],C1=[P2,P3],即Ci = [P(i * M),P((i + 1) * M -1)]如何保证kafka消费者消费数据是全局有序的
伪命题
如果要全局有序的,必须保证生产有序,存储有序,消费有序。
由于生产可以做集群,存储可以分片,消费可以设置为一个consumerGroup,要保证全局有序,就需要保证每个环节都有序。
只有一个可能,就是一个生产者,一个partition,一个消费者。这种场景和大数据应用场景相悖。 4kafka原理



