hadoop的4种运行方法
介绍一下我一些信息:
我是在ubuntu18.04 上开发的mapreduce程序 ,
我的hadoop集群是在我电脑的3台虚拟机上安装的集群,
并且开发工具是idea !
以下实例我都用wordcount程序演示
1 mapreduce程序本地运行 输入数据在本地 输出数据在本地
idea运行程序
输入数据在本地就是在我ubuntu18.04的电脑上:/home/dengtao/wordcount/input
输出数据也是在我本地电脑上: /home/dengtao/wordcount/output
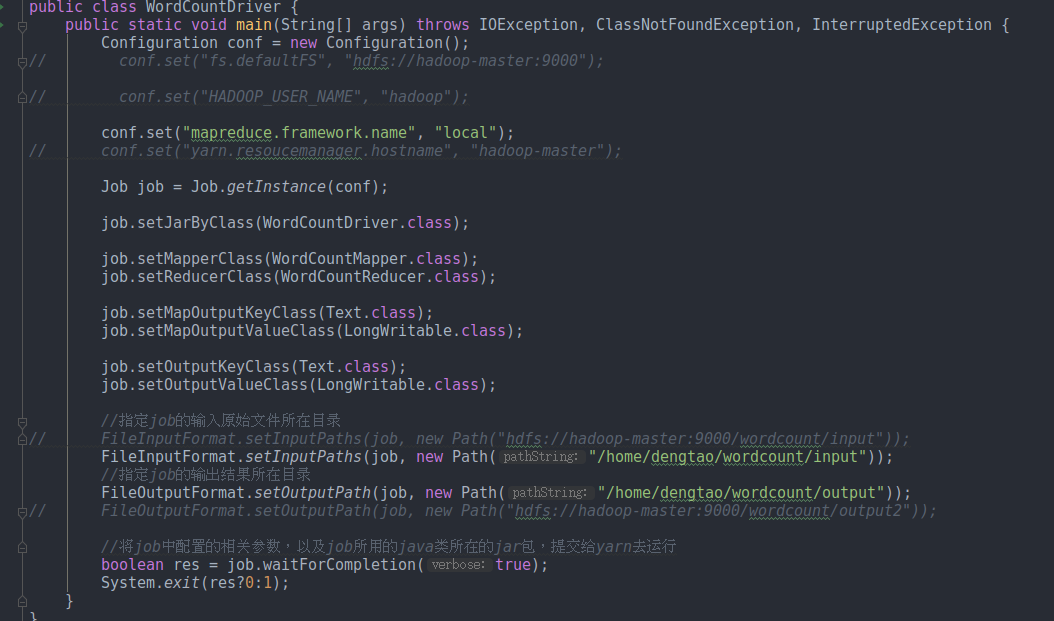
在我的WordCountDriver中配置文件是这样的:
Configuration conf = new Configuration();
conf.set("mapreduce.framework.name", "local"); 可以要也可以不要
//指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path("/home/dengtao/wordcount/input"));
//指定job的输出结果所在目录
FileOutputFormat.setOutputPath(job, new Path("/home/dengtao/wordcount/output"));
在idea中直接运行main方法 最后的效果是这样的:


2 mapreduce程序本地运行 输入数据在hdfs 输出数据在hdfs
idea运行程序
输入数据在hdfs://hadoop-master/wordcount/input
输出数据在hhdfs://hadoop-master/wordcount/ouput
在我的WordCountDriver中配置文件是这样的:
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hadoop-master:9000");
conf.set("HADOOP_USER_NAME", "hadoop");
//指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path("hdfs://hadoop-master:9000/wordcount/input"));
//指定job的输出结果所在目录
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop-master:9000/wordcount/output3"));前提先启动hadoop集群
在idea中直接运行main方法 最后的效果是这样的:

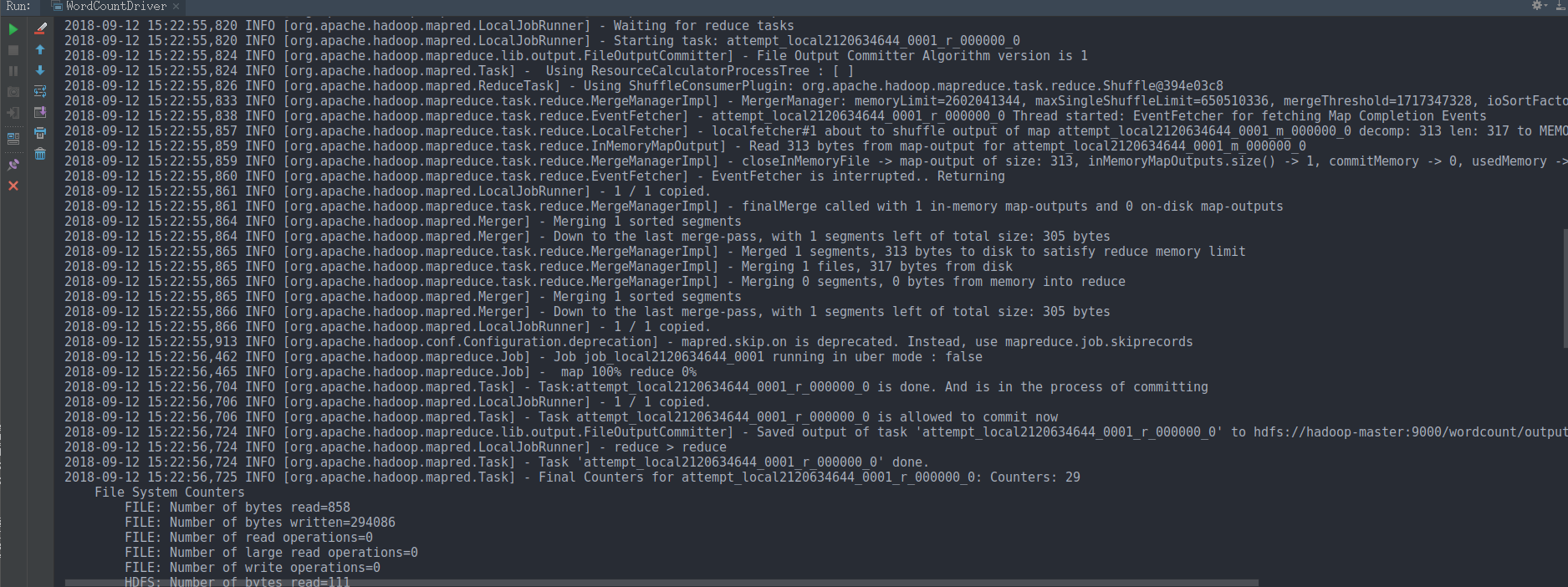

3 mapreduce程序在yarn上运行 输入数据在hdfs 输出数据在hdfs
不在上idea运行程序
这一种方法是要将mr程序打成jar包上传到Hadoop集群, 然后提交任务给yarn运行
配置文件:
1 pom文件:
<build>
<finalName>wordcount</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>2 主配置文件:
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hadoop-master:9000");
conf.set("HADOOP_USER_NAME", "hadoop");
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resoucemanager.hostname", "hadoop-master");
//指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path("hdfs://hadoop-master:9000/wordcount/input"));
//指定job的输出结果所在目录
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop-master:9000/wordcount/output4"));3 打成jar包上传到Hadoop集群

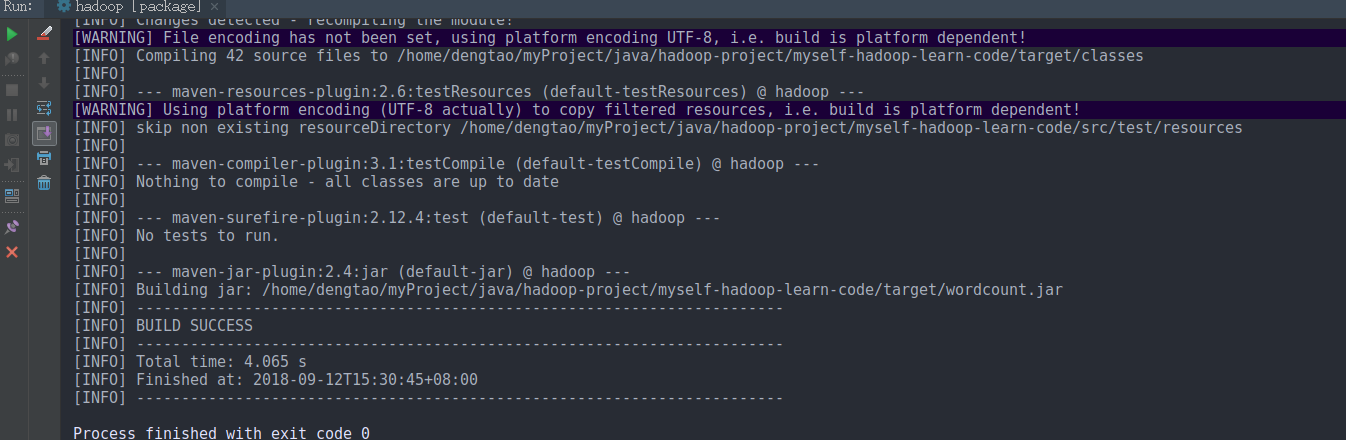
scp wordcount.jar hadoop@192.168.56.90:~/
4 在hadoop集群上运行mr程序
hadoop jar wordcount.jar com.datachina.hadoop.mapreduce.wordcount.WordCountDriver


4 mapreduce程序在yarn上运行 输入数据在hdfs 输出数据在hdfs
也就是说idea远程调试mapreduce程序
idea运行程序
配置文件:
1 pom文件:
<build>
<finalName>wordcount</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>2 主配置文件:
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hadoop-master:9000");
conf.set("HADOOP_USER_NAME", "hadoop");
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resoucemanager.hostname", "hadoop-master");
conf.set("yarn.resourcemanager.address", "hadoop-master:8032");
Job job = Job.getInstance(conf);
job.setJar("/home/dengtao/myProject/java/hadoop-project/myself-hadoop-learn-code/target/wordcount.jar");
//指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path("hdfs://hadoop-master:9000/wordcount/input"));
//指定job的输出结果所在目录
FileOutputFormat.setOutputPath(job, new Path("hdfs://hadoop-master:9000/wordcount/output5"));3 打成jar包
4 运行mapreduce程序
为什么?
2018-09-12 17:13:08,688 WARN [org.apache.hadoop.util.NativeCodeLoader] - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2018-09-12 17:13:09,239 INFO [org.apache.hadoop.yarn.client.RMProxy] - Connecting to ResourceManager at hadoop-master/192.168.56.90:8032
2018-09-12 17:13:09,629 WARN [org.apache.hadoop.mapreduce.JobResourceUploader] - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2018-09-12 17:13:10,781 INFO [org.apache.hadoop.mapreduce.lib.input.FileInputFormat] - Total input paths to process : 1
2018-09-12 17:13:10,902 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - number of splits:1
2018-09-12 17:13:10,996 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - Submitting tokens for job: job_1536743562408_0001
2018-09-12 17:13:11,258 INFO [org.apache.hadoop.yarn.client.api.impl.YarnClientImpl] - Submitted application application_1536743562408_0001
2018-09-12 17:13:11,287 INFO [org.apache.hadoop.mapreduce.Job] - The url to track the job: http://hadoop-master:8088/proxy/application_1536743562408_0001/
2018-09-12 17:13:11,287 INFO [org.apache.hadoop.mapreduce.Job] - Running job: job_1536743562408_0001程序运行到Running job 卡着不动了??????
**经过一个晚上的调试我终于知道是怎么回事了**
1 配置文件修改
Configuration conf = new Configuration();
设置系统用户
System.setProperty("HADOOP_USER_NAME", "hadoop");
conf.set("fs.defaultFS", "hdfs://hadoop-master:9000");
// conf.set("HADOOP_USER_NAME", "hadoop");
conf.set("mapreduce.framework.name", "yarn");
conf.set("yarn.resoucemanager.hostname", "hadoop-master");
修改地方一:
conf.set("yarn.resourcemanager.address", "hadoop-master:8032");
conf.set("yarn.resourcemanager.resource-tracker.address", "hadoop-master:8031");
conf.set("yarn.resourcemanager.scheduler.address", "hadoop-master:8030");
以上3个配置是我在Hadoop集群的yarn-site.xml中是没有配置的!
如果是在Hadoop集群上运行jar包的话
默认是hadoop-master:8032 或者是hadoop-master:8031等等
但是我在用idea远程调试jar的话那么上面的配置的值是0.0.0.0:8032或者0.0.0.0:8031所以程序会停着不动
修改地方二:
在hadoop集群上启动: mr-jobhistory-daemon.sh start historyserver
conf.set("mapreduce.jobhistory.address", "hadoop-master:10020");
此处是配置一些内存管理,默认是可以不用配置的,但是一旦mr报出内存错误那么就可以设置这几个内存管理的值
// conf.set("yarn.nodemanager.resource.memory-mb", "3072");
// conf.set("yarn.scheduler.minimum-allocation-mb", "2048");
// conf.set("yarn.nodemanager.vmem-pmem-ratio", "2.1");
Job job = Job.getInstance(conf);
job.setJar("/home/dengtao/myProject/java/hadoop-project/myself-hadoop-learn-code/target/wordcount.jar");
// job.setJarByClass(WordCountDriver.class);
如果是远程调试的话一定要在Hadoop集群上开启:
mr-jobhistory-daemon.sh start historyserver
...最终我的主文件为:


5 总结一下上面4种mapreduce程序的运行方式
上面的4种方式仅仅只是Hadoop集群不是HA机制下的mr程序运行方式
如果hadoop集群是ha的话:配置会有一些改动 下次再写吧!


